
Vision-Language Models are Weirdly Good at Old Korean
I stress test VLMs on Old-Korean and it works weirdly well.

OCR has changed substantially in the last few years. For clean, modern, printed English, the task no longer usually requires a dedicated OCR engine, a domain-specific training set, or extensive preprocessing. Current vision-language models can often transcribe such material directly from a prompt, sometimes zero-shot and sometimes with a single example. In that limited sense, printed Latin-script OCR for high-resource, modern material has become a largely infrastructural problem rather than a central research challenge.
Historical documents are still harder. Old paper, damaged scans, unusual layouts, handwriting, and older typefaces all push modern models well outside their comfort zone. But even here the progress has been striking. Platforms like Transkribus routinely read European manuscripts that would have seemed hopeless a decade ago, and projects such as Loghi report similarly strong results on historical print. OCR has become much more accessible.
Korean, and by extension CJK1 and other non-Western scripts, is a different case, and early-twentieth-century Korean is different again. Pre-1933, Korean was written in an orthography that has since fallen out of use. It spelled words closer to how they sounded than to a fixed stem, and it kept letters the modern keyboard has dropped, among them the dot vowel arae-a (ㆍ) and a set of old consonant clusters. The spelling we read today is the Unified Orthography of 1933 (한글 맞춤법 통일안), the morphophonemic standard carried by Chu Sigyŏng’s lineage in the Korean Language Society, and it became the convention only after a long argument that ran through the colonial period and resurfaced in the spelling crisis of the early 1950s.2
Modern Korean OCR remains less stable than the English and European-script cases above. On the Korean portion of the PM4Bench benchmark the leading system changes with each new model release, and in the current version Gemini 3 Pro ranks ahead of the newest open model, Qwen3-VL, which does not improve on its own predecessor for this task. This should be read as a relative ranking within a weak field rather than as evidence of reliable transcription. The absolute scores remain low.
In one of my projects, I need OCR labels for about ninety-four million individual character images. Because I study the appearance of historical type rather than the content of the text, it is important that older Korean characters are transcribed as they were printed, rather than silently modernized. This post explores how well current models actually do.
A few tests pages
The page is from Sonyŏn (소년), a children’s magazine published in 1908, and contains a chain-rhyme word game. It is printed in vertical columns read from right to left, combining (Old-)Korean Hangul and Hanja on the same page. Material like this has traditionally been difficult for OCR systems.

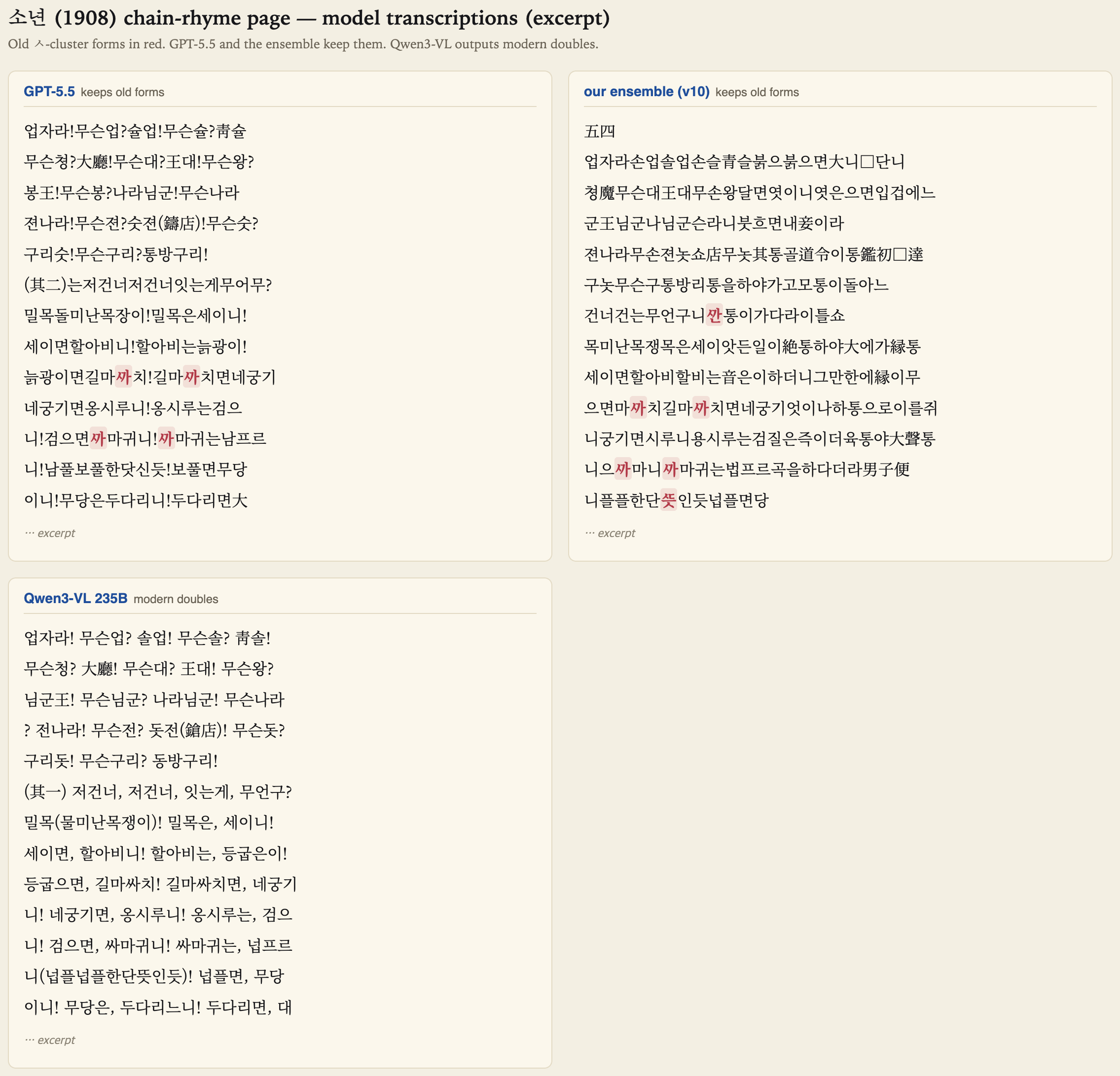
The part I cared about was not whether the models could produce readable Korean. (Though even this would be helpful for many historians.) It was whether they would OCR Korean letters as printed. Before the 1933 spelling reform, Korean used forms that later disappeared or changed in ordinary writing. These include the dot-vowel arae-a (ㆍ) and several old consonant clusters. A model can read a page fluently and still normalize those forms into modern Korean. For most readers the output still looks right. For my purposes, it is wrong.
The first page was a narrow test. It happened to contain two old cluster forms, ᄭᅡ and ᄯᅱ. A modern transcription would normally write these as 까 and 뛰. GPT-5.5 kept all six occurrences of those old clusters on every run. The previous GPT model had modernized all six. That was already a meaningful change, but it did not prove much beyond this particular page.
So I tried five more pages from Sonyŏn, using prose and dialogue rather than word games. These pages contained a wider range of old Korean forms: arae-a in forms such as ᄒᆞ and ᄂᆞᆫ, several ㅅ-cluster groups such as ㅺ, ㅼ, and ㅽ, and even the rarer triple cluster ㅴ. This was the real test. The question was no longer whether a model could preserve two repeated forms on one page, but whether it could keep a broader old-orthography repertoire across different pages.
The current models can preserve old Korean forms, but not with equal reliability. Preservation is still something to check, not something to assume. In practice I treated an old form as trustworthy only when different models produced it, because a single model can also hallucinate plausible old-looking Korean.
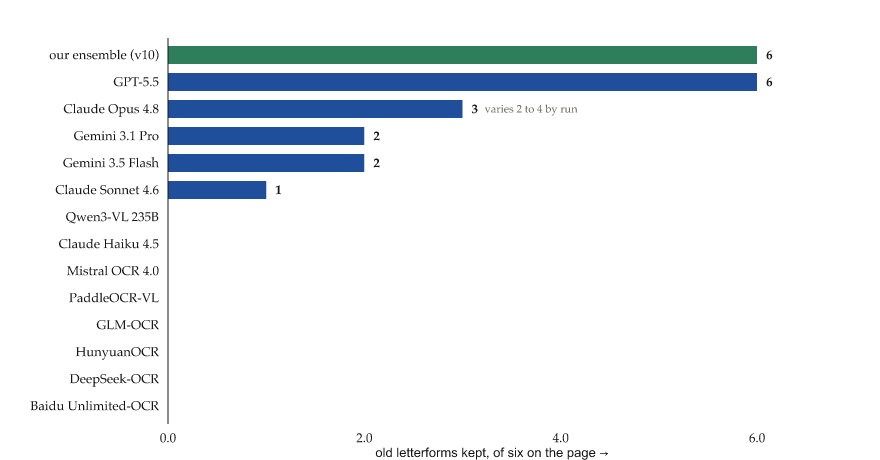
The dedicated OCR engines were not trained on any form of old-Korean and not surprising that they performed the poorest. Mistral OCR, DeepSeek-OCR, Baidu’s Unlimited-OCR, GLM-OCR, all read the page and then modernized the old letters or fell apart, one of them looping a few character lines a few hundred times, another reading the Hangul as Chinese and drifting into a gibberish. Qwen3-VL was different. It read the Korean fluently, but silently regularized every older form into modern Korean. If your goal is simply to recover the text, that is a respectable result. If you care about preserving historical orthography, it is not.
Going back further, to 1896
After Sonyŏn, I wanted to know how the models handled even earlier Korean print. As a final test, I tried the front page of the Tongnip Sinmun (독립신문, The Independent) from 1896, the first privately published Korean newspaper, set entirely in Hangul in the full old orthography with arae-a in almost every word. The only scan I could find is small, a single 960-pixel page, which makes it a hard test on top of an old one. For once there was something solid to check it against. The Korean Wikisource was manually transcribed, so this is the one page in the whole exercise I could measure against ground truth rather than judge by eye. It should also be noted that this newspaper image is denser and has a more difficult layout then the previous magazine had.

Most models struggled. Claude Opus 4.8 transcribed only about a sixth of the page, even reversing the masthead. Qwen3-VL reached roughly two thirds, but regularized the spelling throughout. Both ended up at around ninety percent character error against the Wikisource transcription.
Gemini 3.1 Pro was the clear exception. It read essentially the entire page, from the masthead through the advertisements and price table to the end of the editorial, about ninety-six percent of the page by length. Compared against the Wikisource transcription, it reached roughly seventeen percent character error while preserving 176 of the page’s 182 arae-a. On a 960-pixel scan of an 1896 newspaper, that amounts to a complete transcription of a full old-orthography page.
GPT-5.5 failed for a different reason. It did not misread the page so much as fail to read it at all. Tongnip Sinmun is one of the most famous newspapers in Korean history, and its first issue has been reproduced countless times. When shown the thirteenth issue, GPT-5.5 instead reproduced the first: its date, issue number, and opening lines, at both image resolutions. Against the actual page, the result is about eighty percent character error. It is a useful reminder that, for well-known historical documents, a model can sometimes retrieve what it already knows instead of reading what is actually in front of it.

Why this matters to someone working with the sources
The interesting part is not the benchmark. It is what happens to the historical record.
When the National Institute of Korean History transcribes historical print, it modernizes the spelling. I checked the roughly six hundred thousand colonial-era records they have published, and almost none preserve the older letters. For anyone searching the archive, the original orthography has effectively disappeared.
That makes preservation more than a technical curiosity. A model that keeps the old letters is not simply producing another transcription. It is recovering information that was lost during digitization. For anyone working with pre-1933 Korean print, this may be of importance.
The preservation results only matter if the models can also read the page accurately. On that front, the picture is encouraging. Against four pages of the 1921 magazine Kaebyŏk, where a modern transcription exists, the best current models matched roughly ninety-seven percent of the printed characters directly from the low-resolution scans. That measures reading rather than preservation, since the 1921 transcription already modernizes the spelling. Taken together, though, the results point in the same direction. Current models can read these pages, and on sufficiently old material, the best of them also preserve what makes them historically distinctive.
A note on scale
For a single page, I would use a frontier vision-language model every time.
My own project is different. It involves millions of character crops. Running a frontier model over that volume would incur substantial API costs.
Instead, I built a small voting system with more traditional OCR engines. EasyOCR and a lightweight classifier trained on historical Korean type recognize the Old-Korean, PaddleOCR reads the Hanja, and a simple voting rule chooses between them. The entire corpus finished in about a week on hardware we already owned.

The ensemble has one advantage over a frontier model besides cost. It is explicit about uncertainty. When its engines disagree, it leaves the character blank instead of guessing. A frontier model often does the opposite. It produces a perfectly plausible modern character, and unless you compare it with the original page you may never realize the historical form has disappeared. A blank is an error you can revisit. Silent modernization is much harder to detect.

What this adds up to
For anyone working with pre-1933 Korean print, the practical picture has changed. Current vision-language models can do more than transcribe these pages. The strongest of them can preserve historical orthography that is absent from most digital editions. It can also help one quickly digitize small (or large) amount of works. However for very large datasets cost can quickly skyrocket. It might be worth distilling some of this knowledge into a smaller, more specific model to save on API costs.
That does not mean OCR has been fully solved. The results are model-dependent, page-dependent, and, as far as I can tell, language-dependent. But for this particular corner of the problem, the gap between what was possible a few years ago and what is possible today is surprisingly large.
Chinese-Korean-Japanese
Kim, Michael. “The Han’gŭl Crisis and Language Standardization: Clashing Orthographic Identities and the Politics of Cultural Construction.” Journal of Korean Studies 22, no. 1 (March 2017): 5–31. https://doi.org/10.1215/21581665-4153412.