
A council of models
Exploring how we can use LLMs like a team for empirical research.


This is an extension of part of the presentation on using LLMs in research pipelines I gave for Machine Collaborators, series of talks organized by Charles Crabtree (Monash University) where researchers walk through how AI is being used in their work.
OpenRouter recently announced a product called Fusion, which routes a single question through a panel of cheaper models at once and reports that such a panel can come within a point of a frontier model's score at about half the cost. The marketing is new, but the idea a bit less so. Pitting several models against one another has become a standard way to use language models for finding optimal ideas and outcomes. For empirical research, what use might it have?
I have used a similar setup in two of my own studies. In one, six models read roughly four thousand open-ended survey answers and sorted each into a code, helping me determine what respondents were actually thinking when they navigated a survey experiment. In the other, four models read sixty-seven Korean history textbooks and, using a term extraction technique I created, determined which words best reflected national identity. Sorting answers into fixed codes and discovering which words matter are different problems, but the instrument is the same. It is a panel of open-weight language models, treated as a team of independent coders, voting.
In this piece I reflect on how it works, why I run it mostly on open-weight models, how it relates to the “councils” that Fusion and others have started to build, and what it does and does not support you, as a researcher, doing. The short version is that it works well, that for coding tasks it holds up against the human labor it replaces, and that its central value is scale rather than certainty.
The method: open models as a panel of coders
Take a judgment a trained research assistant would make, such as reading a piece of text and deciding what it is about, and give it to several models at once, each with the same codebook and the same instructions. Each model receives the same text, the same instructions, and the same codebook, then returns a single labeled decision. The panel's majority vote becomes the classification, while the number of models supporting that decision is recorded as a measure of agreement.
Two features of this design matter for the steps that follow. First, I treat each model as a coder. I ask it to assign a label, much as I would ask a trained research assistant, rather than relying on its probability distribution or confidence estimates. (More on this below.) I ask it for a labeled decision, the way I would ask a research assistant, and I read the spread of decisions across the panel the way content analysts read inter-coder reliability, with chance-corrected statistics such as Cohen’s and Fleiss’ kappa. Second, the models vote independently. They run at temperature zero (i.e., no “creativity” permitted), they do not see one another’s answers, and there is no deliberation. Any sense in which the models are played off against one another happens afterward when I line the votes up and read where they part ways.
I run the panel mostly on open-weight models. A proprietary model behind an API can change between versions, and its outputs cannot be reproduced exactly by another researcher. Open-weight models, run locally at a fixed temperature and seed, return the same answers when re-run in the same environment, which is what reproducible measurement requires. In the classification study I still included one proprietary model, GPT-4o-mini, as a convenient reference coder, because it is inexpensive, fast, and unusually capable on the Korean and Traditional Chinese text those projects involved. The term-extraction panel below is fully open-weight. But GPT-4o-mini is one voice on a panel that is otherwise open and re-runnable, not the authority on it.1

An example of the method. One open-text response from a survey is read by six models that vote independently. The majority becomes the code, and the size of the majority is recorded as a reliability signal.
Three ways to convene a council
The instinct to put models in concert has been built in several distinct ways, and they are worth separating, because they are not after the same thing.
Fusion is the production version. A panel of models answers in parallel, a judge model reads every answer and writes a structured account of where they agree, where they contradict, and what they all missed, and the calling model writes the final answer grounded in that account. What Fusion optimizes is the quality of one answer against its cost, which is why its own documentation says it is not a drop-in replacement and is worth the expense only when a question warrants several perspectives. The models often arrive at different conclusions, but those differences are resolved internally rather than exposed to the user.
Sakana AI’s Fugu uses the same basic approach. Rather than sending every query to a fixed panel of models in parallel, it uses a trained orchestration model to decide whether and when to delegate, select and coordinate models from an agent pool, verify their work, and synthesize the results into a single answer. The system is exposed through one model API, so the complexity of multi-model coordination never reaches your code.
Two other versions come from computer and political science. Andrej Karpathy's llm-council has several models answer, then rank one another with their identities hidden, before a chairman model writes a final answer. Andrew Hall's llm-council-governance extends that logic into an experiment on the decision rule itself, comparing seven governance procedures, from simple majority voting to deliberate-then-vote, on problems with verifiable answers. Deliberation followed by a vote performed best, at 80.9 percent against 71.7 for the strongest single model. There is also an academic Language Model Council in which twenty models write tests, answer them, and grade one another to produce rankings that track human judgment more closely than any single model does.
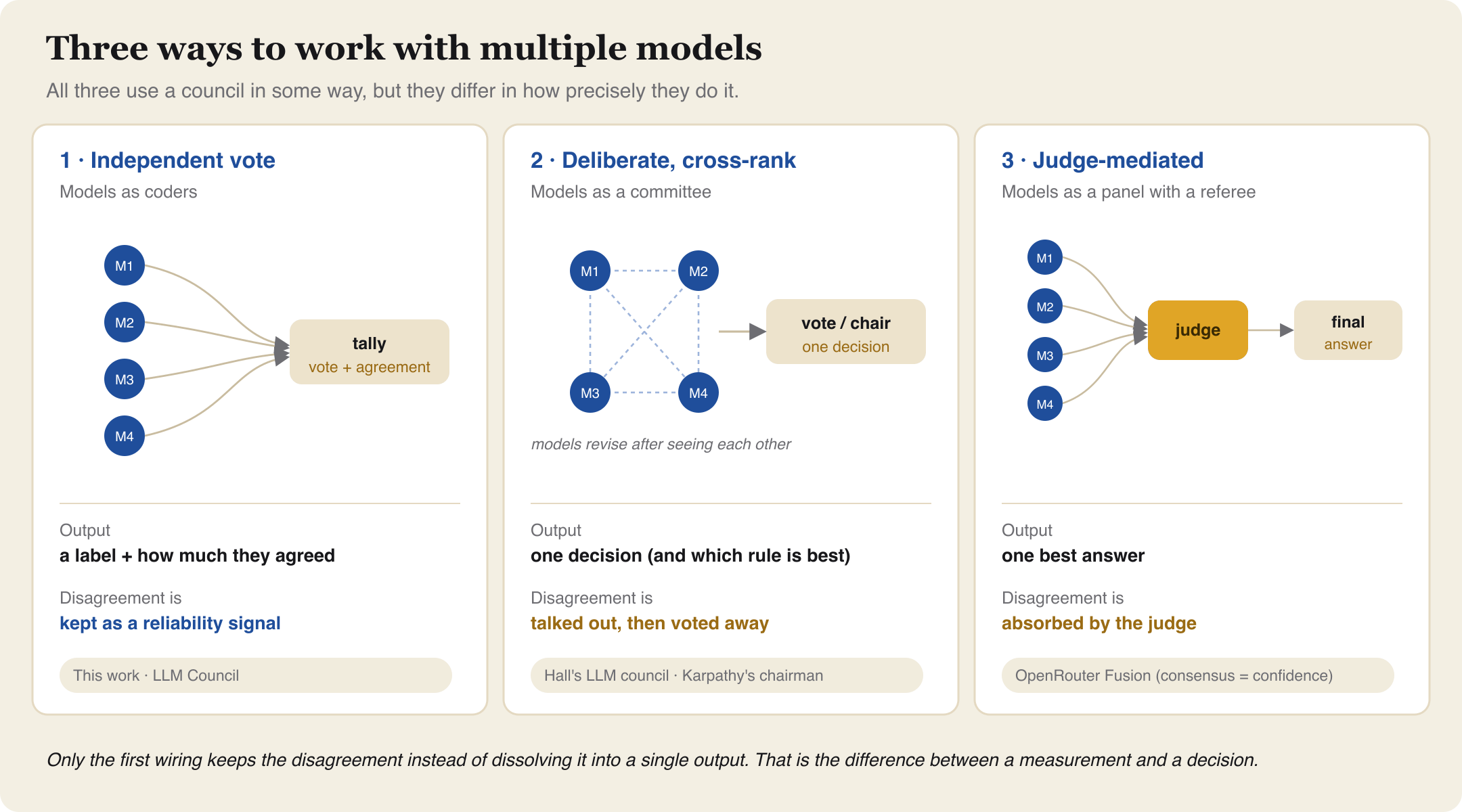
Three ways to wire a panel of models. All draw on the same lineage. They differ in what they do with the disagreement.
The resemblance is close enough that the model lineups overlap. Hall's council runs Qwen, Llama, Gemma, and Mistral. The classification panel below runs Qwen, Llama, Gemma, and three others. What separates my use from the rest is the last step. Fusion and the councils collapse the panel into a single output, an answer or a decision, and discard the spread behind it. Hall's experiment even finds that deliberation before the vote produces the best single answer, which is the right goal when you want one answer and the wrong one when the spread is the thing you are trying to measure. So I keep the spread, because in a measurement task the agreement, or the lack of it, is itself a quantity of interest. It helps to think of each model as a coder rather than a black box. Each one assigns a label, the panel may agree or divide, and each carries some uncertainty of its own. Those are the qualities I want to read, not average away.
Application one: classification
Take classification first. My thinking on this grew out of my working paper, "What Were They Thinking?", which asks how to validate survey constructs in conjoint designs using the open-text data usually collected only for manipulation checks. A conjoint experiment tells you what respondents chose, but rarely whether they reasoned about the choice the way the design assumes. To find out, I embedded an open-ended question after the conjoint task ("Why did you choose this person?") and coded the answers into a small set of categories. The corpus is about four thousand short answers in Korean and Traditional Chinese, from naturalization experiments in South Korea and Taiwan, where respondents weighed who deserves to be prioritized for citizenship. The codebook the models worked from had five codes: civic commitment, functional integration, economic focus, identity concern, and a none-of-the-above residual.
Six models coded every answer: GPT-4o-mini together with five open-weight models run locally through Ollama, spanning Qwen 2.5 at 3B, 32B, and 72B, Llama 3.1 8B, and Gemma 3 12B. A response is granted a classification when at least four of the six agree. Across the corpus the panel’s chance-corrected agreement is a Fleiss’ kappa of about 0.74, which content analysts would call substantial. As more of the six models converge on a label, each model is also individually more confident in it, and the unanimous cases are, likely, the ones a researcher could reasonably trust. The split cases, where the panel divides three against three, are the cases worth handing to a human reader or dealing with in another way.
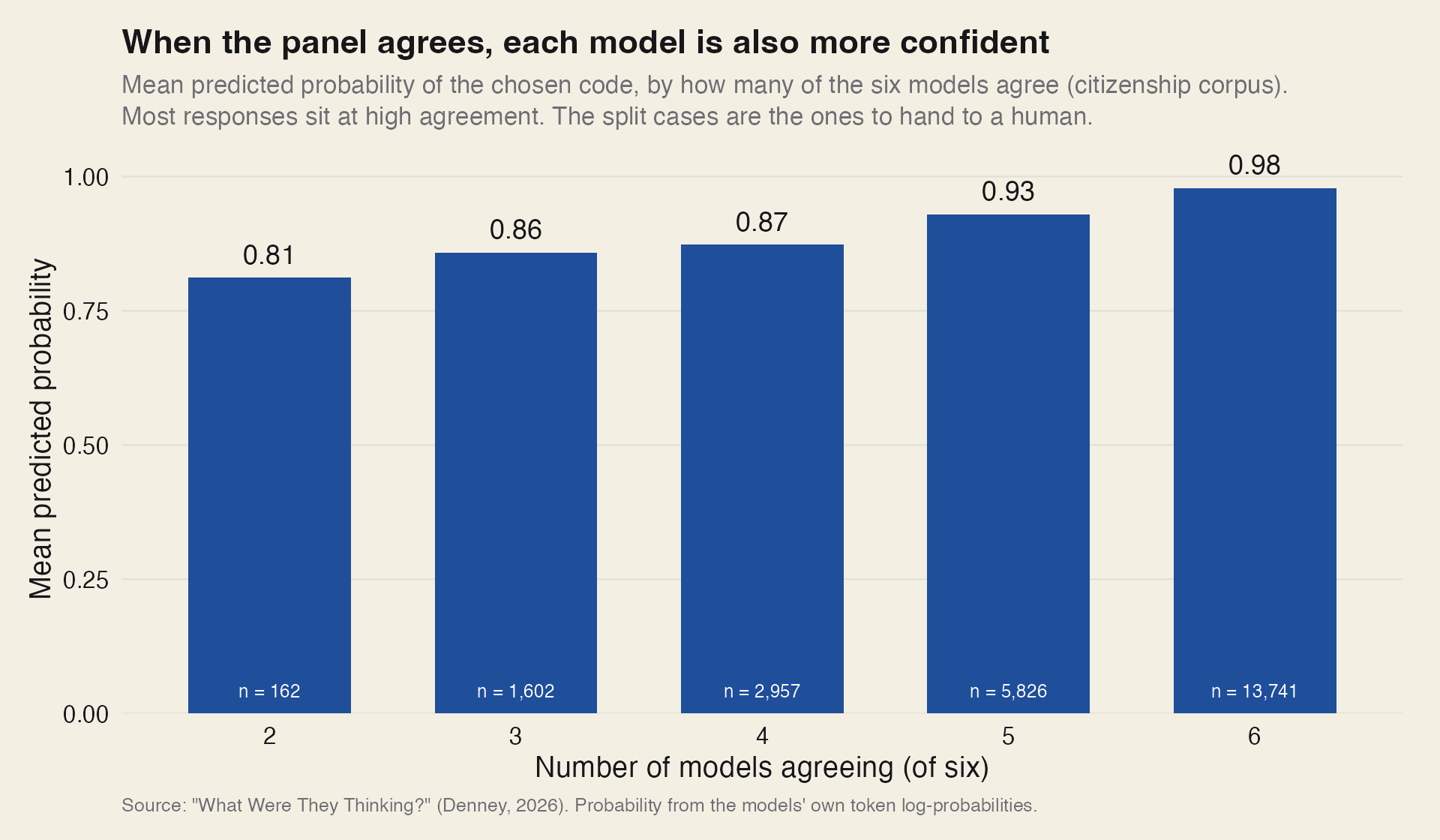
As more of the six models agree on a code, each model is also individually more confident in it. Most answers sit at high agreement. The split cases are the ones to review by hand.
Two things make this more than a cost-saving trick. The first is scale. Hand-coding four thousand multilingual answers to a publishable standard, with two trained coders and an adjudication protocol, is a substantial project on its own, and it does not scale to the next survey or the one after that. A panel of models codes the full corpus in an afternoon and recodes it with ease, assuming a replicable setup, if the codebook is updated.
The second is quality. I do not treat the models as a cheap approximation of a human coder so much as a fast one that reasons about a short, context-dependent answer in much the way a careful human reader would. Where I had human-coded ground truth and the panel disagreed with it, I read the disputed cases myself, and more often than not I judged the model's label the better one.2 This is consistent with Ryan Briggs and colleagues, who used language models to extract validated data from roughly one hundred thousand political science articles, putting model coding to work at a scale hand-coding could not reach.3
Not every disagreement is the model's mistake to absorb, though. Some are a sign that the codebook is unclear, and those are the ones to chase, because the codebook is the part you actually tune. When I first checked the panel against human-coded ground truth, the agreement was only fair. Reading the misses in a batch, rather than one at a time, showed the models were applying two of my categories the way I had written them and not the way I meant them: one defined too narrowly, the catch-all residual left too broad. I rewrote those definitions, ran the panel again, and looked again, and over two rounds the agreement with the human codes rose from a fair kappa near 0.40 to a substantial one near 0.67. That gain was larger than anything I got from swapping in a bigger model. The model is the coder. The codebook is its instructions, and calibrating the instructions against a few hundred of your own annotations is where most of the accuracy is won.
Application two: finding the words that matter
The second use case approaches the use of multiple LLMs a bit differently. In "Constructing the Nation," written with Aron van de Pol, I study how South Korean history textbooks portray national identity across the postwar decades. This time there is no codebook to apply. The categories themselves are the quantity of interest. We set out to find which words carry the weight of national identity in the corpus, and how their use changes over time.
The standard tool for extracting terms, concepts, or words from a corpus is topic modeling. The standard topic model is Latent Dirichlet Allocation. LDA treats each document as a bag of words and groups terms that co-occur. It is fast and unsupervised, and it is indifferent to context. A word that means one thing in a sentence about colonial resistance and another in a sentence about economic development is the same token to LDA. For a corpus of long, discursive textbook chapters, where the meaning of a term such as minjok (nation, or ethnos) gets its meaning from the sentences around it, the lack of context being taken into account is a real limitation.
An LLM approach handles it differently. Four large models, each from a different country's lab, read the corpus in long passages and propose the identity-related terms they find: EXAONE from Korea, Aya Expanse from Canada, Qwen from China, and Gemma from the United States. A term enters the final set only when at least three of the four propose it, after which each candidate has to clear a corpus-frequency and semantic-similarity check. The models were chosen from different training traditions on purpose, so that agreement across them would mean more than agreement among near-copies. The result is a set of nine defining terms.
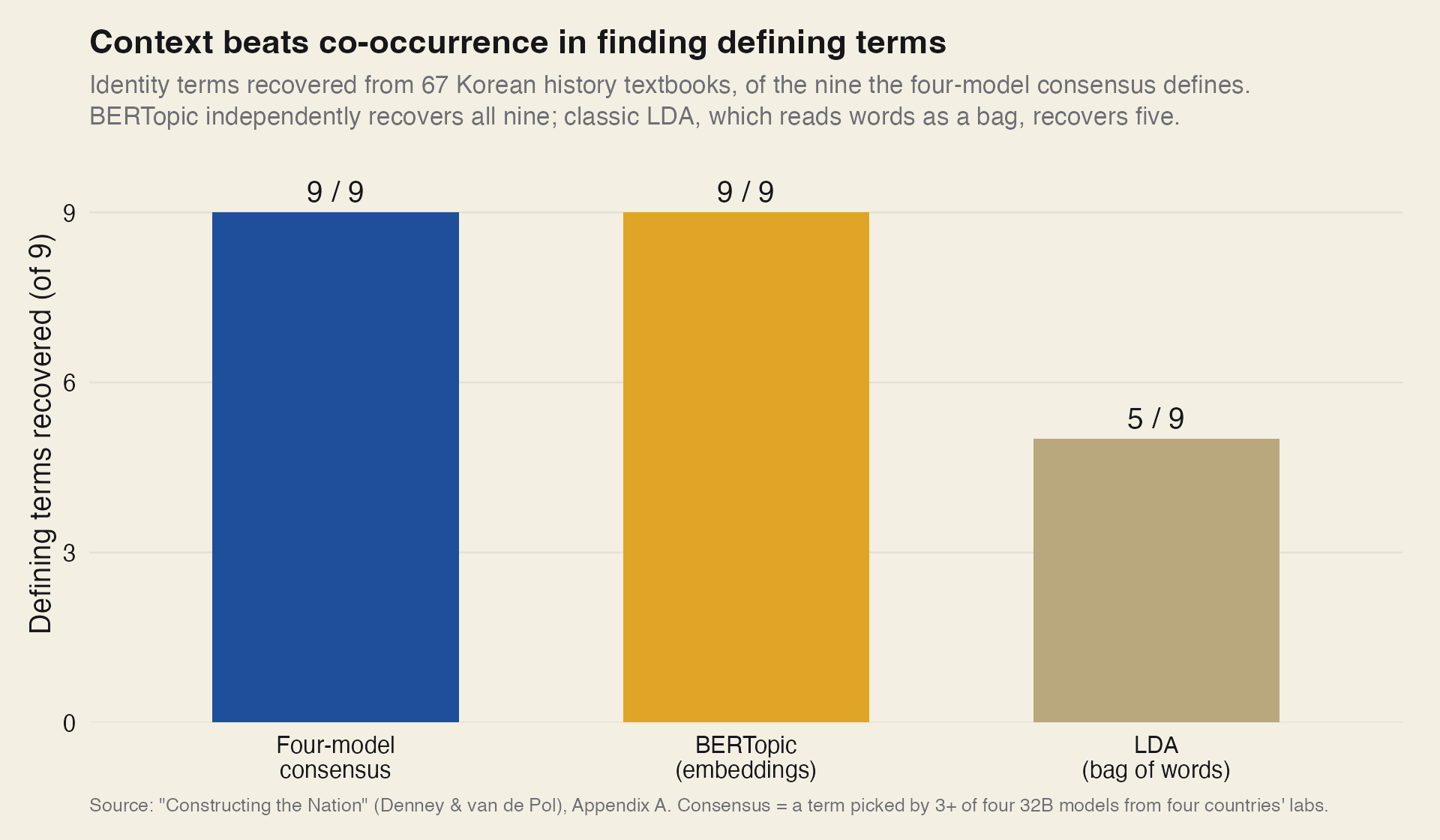
Of the nine terms the four-model consensus defines, an embedding-based topic model identifies all nine, while classic LDA identifies five. Context-aware methods find terms that bag-of-words co-occurrence misses.
As a check, we ran an embedding-based topic model, BERTopic, which reads words in context. It identified all nine, with far fewer edge cases than the bag-of-words baseline. BERTopic does not read a textbook whole, though. Its embedding model takes in short passages at a time, because its context window holds only so many tokens.
An LLM faces the same limit, only a much larger one. It cannot take in a whole book at once either, since the text would exceed its context window and be rejected or truncated, but its window is wide enough to read a term against far more of the surrounding passage, and you can window across a long document in overlapping batches. That extra room is where the real difference shows up.
Classic LDA, for what it is worth, identifies only five terms. The panel of LLMs does what topic modeling is meant to do: name the vocabulary that organizes a corpus. But it reads each term in the context of the passage around it, the way a human reader of these textbooks would, and it identifies terms that word co-occurrence alone misses. For a corpus of long documents, that is the difference between a list of frequent words and a list of meaningful ones.
What LLM voting does and does not measure
There are, of course, limits. Cross-model agreement is a measure of reliability, not of validity, and it is not a calibrated estimate of uncertainty. The panel can agree because the answer is clear, and it can agree because the models share training data and therefore share blind spots. The Condorcet jury theorem, which is the formal reason a majority of independent voters grows more accurate as the panel grows, assumes the voters are independent, and language models are not. Their errors are correlated, so a panel of nine carries far less independent information than nine human coders would.4 Agreement should therefore be reported as inter-coder consistency among non-independent coders, rather than accuracy or probability.
This limit is notable, but it is not, in my experience, the main thing. On the one task where I had adjudicated human codes to check against, which came from a separate corpus on North Korean entrepreneurs rather than the citizenship answers above, the models agreed with the human coders at a substantial level, short of the agreement between the humans themselves, and in the cases where they differed I usually sided with the model. The limit imposes modest discipline. Keep some human-coded ground truth in the project, if you can, even a few hundred cases, so that the panel can be checked rather than trusted on faith. Where a within-model confidence is needed, read it from the model's own token probabilities, which come from its predictive distribution, rather than from the agreement count or a model's self-reported confidence.
That last point is worth dwelling on, because if a model is going to stand in for a coder, its uncertainty has to be handled like a coder’s. A careful human coder is not equally certain of every judgment, and neither is a language model. Even with a fixed codebook and temperature set to zero, the model assigns different degrees of confidence to different classifications. That confidence is reflected in the log-probability it assigns to the label it ultimately selects, a quantity derived from the model’s predictive distribution at the moment of the decision. By contrast, a HIGH or LOW confidence tag the model produces if asked is simply another generated response, not a direct measurement of its uncertainty.
I therefore treat the log-probability as an indicator of uncertainty. It records how much probability the model assigned to the label it ultimately selected, according to its predictive distribution. A response that receives a label but a relatively low log-probability is one that merits closer inspection. It captures something the panel does not. The log-probability reflects how certain each model is about its own decision. Agreement across the panel reflects whether different models reach the same decision. The two measures complement one another rather than serving the same purpose.
Is it worth it
It is, if the claim stays within the evidence. A panel of open-weight models is a practical research instrument, and the two applications here show its range. For classification it does the work of a team of coders at a scale no team could match, and codes nearly as well, a little below expert human agreement. For term discovery it does the work of a topic model while reading each term in context, which lets it identify defining vocabulary that bag-of-words methods miss. In both cases the design that makes it trustworthy is the same. Use several models rather than one, choose them to be as different from one another as possible, run them on open weights so the result can be reproduced, and treat a split vote as a flag for human attention rather than as noise to be averaged away.
A panel of LLMs can outperform a single model. But it does not follow that high agreement means the panel is correct. High agreement tells us that these particular models concur, not that they have reached the truth. The two coincide only when the panel is both accurate and sufficiently diverse. Build the panel and pay attention to where it disagrees. But the human stays very much in the loop here, refining the codebook before the run and adjudicating the cases the panel cannot resolve afterward. The panel supplies scale, consistency, and a record of disagreement. The researcher still has to decide what the categories mean, whether the instrument is valid, and when the models and their output should not be trusted.
Using Claude Code
If you want to run something like this yourself, the steps are codified as a set of open-source Claude Code skills I maintain and reach for when working with agents, so each run stays reproducible. The ones closest to this post are model-council-voting, for running a panel and reading its agreement; text-classification, for designing and validating a codebook; and llm-calibration-logprobs, for reading per-decision confidence from token log-probabilities.
The full classification panel is GPT-4o-mini plus five open-weight models run locally via Ollama at temperature zero with a fixed seed: Qwen 2.5 (3B, 32B, 72B), Llama 3.1 (8B), and Gemma 3 (12B). The case for running open weights rather than depending on a proprietary API is reproducibility: API models drift between versions and cannot be rerun deterministically (Barrie et al. 2025). GPT-4o-mini earns its place as a reference coder on grounds of cost and strong multilingual performance, not authority, and agreement with it rises monotonically with open-model size (Qwen 2.5: 0.73 at 3B, 0.83 at 32B, 0.86 at 72B), which is a useful sanity check on the smaller models.
The check comes from a separate corpus coding why North Korean entrepreneurs make the choices they do, where two trained humans coded every response. The two humans agree at kappa 0.88. Each model agrees with the humans at about 0.61 to 0.67, roughly what one would expect of a competent third coder. The models are also overconfident against human codes when their token probabilities are read as calibrated estimates (expected calibration error of 0.15 to 0.26, against 0.01 to 0.10 when scored against the panel’s own majority), which is the technical form of the point that agreement is not the same as accuracy.
Briggs, Mellon, and Arel-Bundock, “It must be very hard to publish null results” (working paper). They code a large corpus of articles for whether results are null, using LLMs validated against human coding, and document a steep gap between the share of published abstracts reporting non-null results and the share reporting nulls.
A recent study, “Nine Judges, Two Effective Votes: Correlated Errors Undermine LLM Evaluation Panels” (Kohli 2026), estimates that a panel of nine frontier models from seven families carries only about two independent votes’ worth of information, because the models tend to be wrong on the same items. The remedy is real diversity among the voters, which is the reason the term-discovery panel draws its four models from four different national labs.